Circuit analysis is still too manual.
Even with attribution graphs, the standard workflow is basically expert-guided search: pick a target logit, trace strong incoming features, read labels, follow influence paths backward, and decide which nodes belong in the circuit. For an experienced researcher, that often means "10-15 minutes per prompt" (Jack Lindsey, Anthropic Interpretability Researcher). For anyone less practiced, it can take longer, and the result is still hard to validate.
As Neel Nanda, Interpretability Lead at DeepMind, describes:
"I now feel more excited about attribution graphs. The thing that has clicked a bit more is: I think you can just get a lot of info quite fast if you put in a ton of upfront effort. I'm still not convinced it's worth the ton of upfront effort."
To which Tom McGrath, Goodfire co-founder, responds:
"What if someone else were putting in the upfront effort?"
I built CircuitExplorer to automate that workflow on top of the attribution-graph circuit-tracing approach developed in Anthropic's interpretability work, using Neuronpedia-hosted attribution graphs as the practical substrate.
This post is the short version of the project. It accompanies a longer technical post here. Keep in mind that any place on this post that feels light on the technical details is intentional and most likely has the sought-after technical details covered in the longer post.
The takeaway result is straightforward and directionally promising:
On 15 researcher-verified circuits, CircuitExplorer's graph search algorithm matches expert-crafted circuits on median causal necessity (46.1pp vs 42.5pp) while improving median sufficiency (62.3% vs 51.2%), and it builds circuits in 6 seconds on average instead of ~10 minutes (100x faster).
This result matters because it connects two goals that usually pull in different directions: the system has to find causally useful circuits automatically, and it has to make those circuits easy for researchers to inspect, compare, edit, and validate. CircuitExplorer's interface is part of the research workflow: automation gets a researcher to a strong first-pass circuit, and the UI makes that circuit legible enough to interrogate.
For a visual walkthrough of CircuitExplorer, go here.
The code for CircuitExplorer is available here.
Table of Contents
- The Problem
- The Approach: IA+PC
- Interventions and Causal Validation
- How I Evaluated It
- Main Result
- Workflow Result
- UI Walkthrough: Before and After
- System Architecture
- Do These Circuits Reflect Real Mechanisms?
- Transfer Beyond One Model
- The Main Failure Mode
- What This Shows
- What I Would Do Next
- Closing
The Problem
Anthropic's attribution-graph work makes circuit tracing much more concrete: it gives researchers a graph of features and edges that can be inspected for a specific prompt and target output. But attribution graphs do not remove the hardest part of circuit analysis: choosing the circuit.
For a single prompt and target output, the graph may contain hundreds or thousands of feature nodes and tens of thousands of edges. Somewhere inside that graph is the mechanism you care about. The actual research problem is deciding:
- which features are genuinely important for the target output
- which ones are part of the mechanism rather than merely adjacent to it
- when a circuit is good enough to stop expanding
Without a search procedure and a validation loop, circuit discovery remains a manual craft.
The Approach: IA+PC
CircuitExplorer uses a two-stage graph search strategy I call IA+PC:
- Influence-Aware search (IA) builds a circuit greedily using attribution-graph completeness while biasing toward features with positive target influence.
- Pathway Completion (PC) expands the circuit by adding nearby features that close downstream gaps without substantially degrading completeness.
The important engineering detail is that this search runs directly on the attribution graph's linearized scoring machinery. It does not require model inference during search. Candidate evaluation is matrix-based and cheap, which makes circuit construction fast enough to use interactively and fast enough to benchmark systematically.
That design turns a fuzzy qualitative workflow into something operational:
- automatic candidate generation
- deterministic scoring
- fast iteration
- causal validation after discovery
Interventions and Causal Validation
The validation path matters as much as the discovery and search path though. CircuitExplorer does not stop at graph scores. It runs ablation-based interventions against the model to test whether a circuit is necessary and sufficient for the target output.
For each discovered circuit, the system runs three conditions:
- baseline: the original model behavior on the prompt
- necessity: asks whether the circuit matters: if we ablate the circuit features, how much does the target output probability drop? A higher necessity score means the model relies on those features for the prediction.
- sufficiency: asks whether the circuit is complete: if we ablate everything except the circuit features, how much of the target output probability remains? A higher sufficiency score means the circuit preserves more of the computation on its own.
That turns circuit discovery from a visual hypothesis into a measurable intervention workflow. The graph search proposes a circuit cheaply using attribution-graph linear algebra; the steering and ablation path then checks whether that circuit actually matters in the model.
This distinction is important since graph-side scores are useful for search but don't reveal the ground truth model behavior. The final claim comes from intervening on model internals and measuring behavior. CircuitExplorer keeps those two loops connected: fast graph-side iteration for exploration, model-intervention validation for evidence.
How I Evaluated It
I evaluated CircuitExplorer in four ways.
First, I assembled a researcher comparison set: 15 manually built circuits on Gemma-2-2B with gemmascope-transcoder-16k, traced through the same attribution graphs by reading feature labels, following influence paths, and applying domain knowledge. This is the most important benchmark because it compares the automated system directly against the workflow it is meant to accelerate.
Note: While 15 circuits is not a lot of circuits, it's a decent starting point especially given that they are across different categories.
Second, I ran a broader benchmark on 62 prompts across 9 categories, including factual recall, arithmetic, cross-lingual identification, analogy, syntactic agreement, and related tasks.
Third, I ran a counterfactual prompt-pair analysis on 40 prompt pairs across 8 categories. The goal here was to test whether discovered circuits reflected reusable mechanisms rather than prompt-specific artifacts. If two prompts instantiate the same underlying mechanism with different entities, their circuits should share causally important features.
Fourth, I reran the evaluation on Qwen3-4B with a different transcoder set and no algorithm changes. Model coverage is still constrained by what transcoders exist, but I wanted at least one real transfer check beyond Gemma-2-2B so there'd be some coverage of 1) how the approach performs on a (slightly) larger model (2B vs 4B) and 2) how the approach performs on a different model family.
Main Result
On the 15 researcher-verified circuits:
| Method | Avg Necessity (pp) | Avg Sufficiency |
|---|---|---|
| Researcher | 32.7 | 79.1% |
| Completeness-only (C-only) greedy | 30.8 | 33.3% |
| C-only + Path-Completion | 30.8 | 86.0% |
| IA+PC | 32.7 | 86.2% |
Three things matter here.
First, IA+PC matches the researcher exactly on average causal necessity. That is the strongest evidence that the algorithm is finding features the model actually relies on, not just visually plausible chains.
Second, IA+PC exceeds the researcher on sufficiency. Pathway Completion fills downstream gaps that manual tracing often leaves out.
Third, the method ablation is clean:
- C-only greedy search finds interpretable chains but misses target-specific features
- adding PC closes the sufficiency gap
- adding IA closes the necessity gap
Workflow Result
On Gemma-2-2B:
- manual circuit construction takes roughly 10-15 minutes per prompt
- IA+PC builds a circuit in 6 seconds on average
- the full 62-prompt discovery + causal validation suite was optimized 15x from about 90 minutes to 6 minutes
That 15x evaluation speedup came from looking into the following optimizations:
| Optimization | Effect |
|---|---|
| Server-side PyTorch scoring | moved matrix operations out of client-side JavaScript and cut per-call scoring cost |
scatter_add pin merging |
replaced a Python loop over hundreds of features with one vectorized operation |
| Batched candidate evaluation | scored multiple candidates with a single tensor operation instead of one candidate at a time |
| Batched steer validation | submitted necessity and sufficiency ablations together through /steer-batch |
| Pipelined build and validation | overlapped the next circuit build with the previous circuit's causal validation |
These optimizations provide one main takeaway:
CircuitExplorer gets a researcher to a causally useful starting point almost immediately, so they can spend more time interrogating mechanisms and less time building circuits by hand
UI Walkthrough: Before and After
The UI matters because attribution graphs are not self-explanatory objects. A graph can contain hundreds of feature nodes, many more edges, and multiple plausible paths from prompt tokens to a target logit. Without interaction design that supports the research workflow, automation just produces another object a researcher has to decode.
The baseline Neuronpedia graph view is useful for inspecting attribution graphs, but the circuit-building loop is still mostly manual:
- start from the target output
- click through high-influence features
- read feature labels one by one
- pin the features that seem relevant
- mentally track whether the circuit is becoming more complete
- run causal tests only after a candidate circuit has been assembled
That manual loop is exactly what Jack Lindsey describes:
"This experience you just had of tracing through this graph, lumping together nodes, trying some steering was reasonably reflective of what the typical experience is like... You found a bunch of features, you were able to trace a decent scaffold of a story of how this stuff came to be... There were some weird features, some polysemantic features that we kind of just ignored. There were multiple mechanisms going on at once — direct paths and also more 'lookupy' paths. Sometimes those were kind of fuzzy."
CircuitExplorer changes that loop from manual tracing into an automated workbench.
| Before: attribution graph viewer | After: CircuitExplorer workbench |
|---|---|
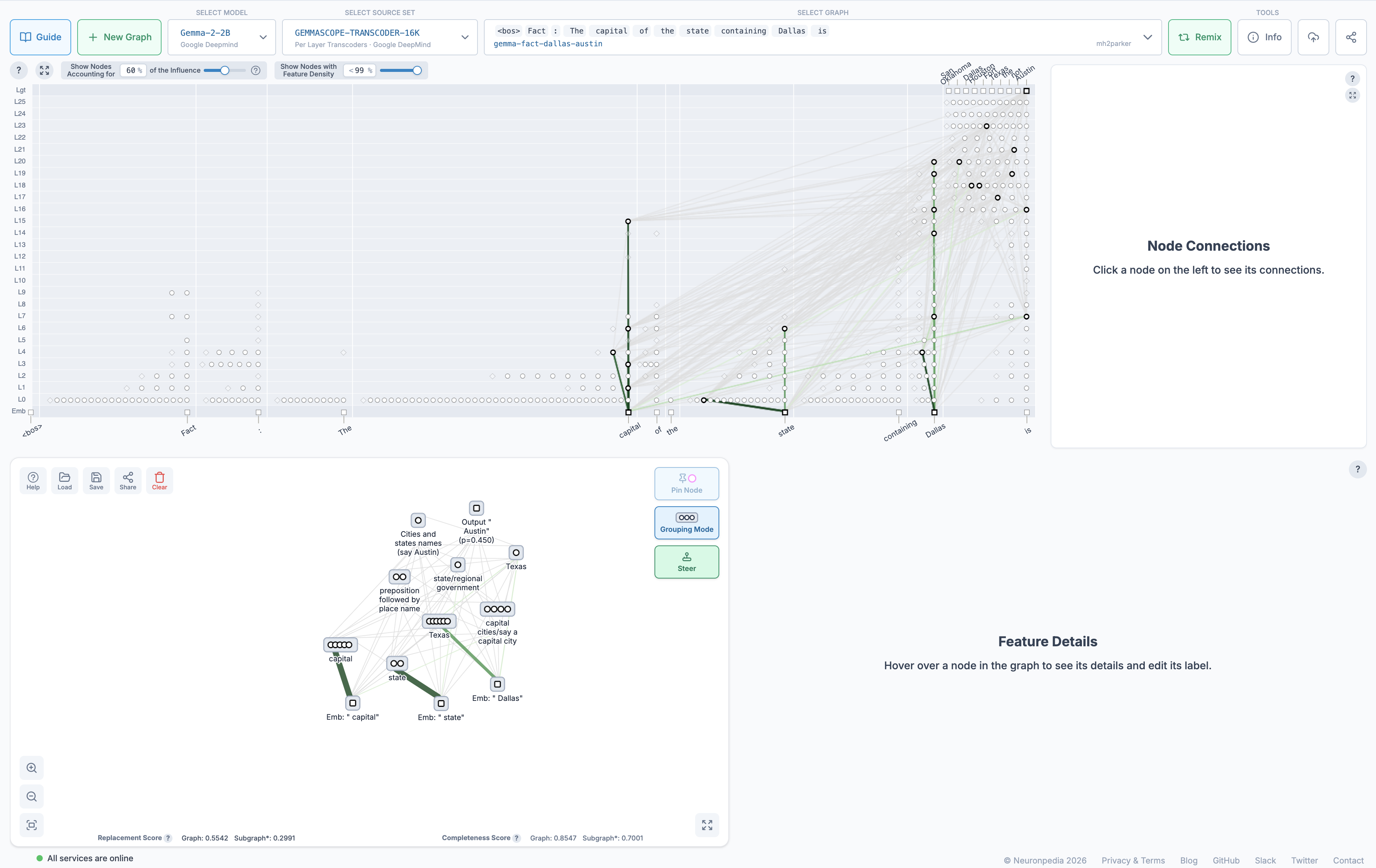 |
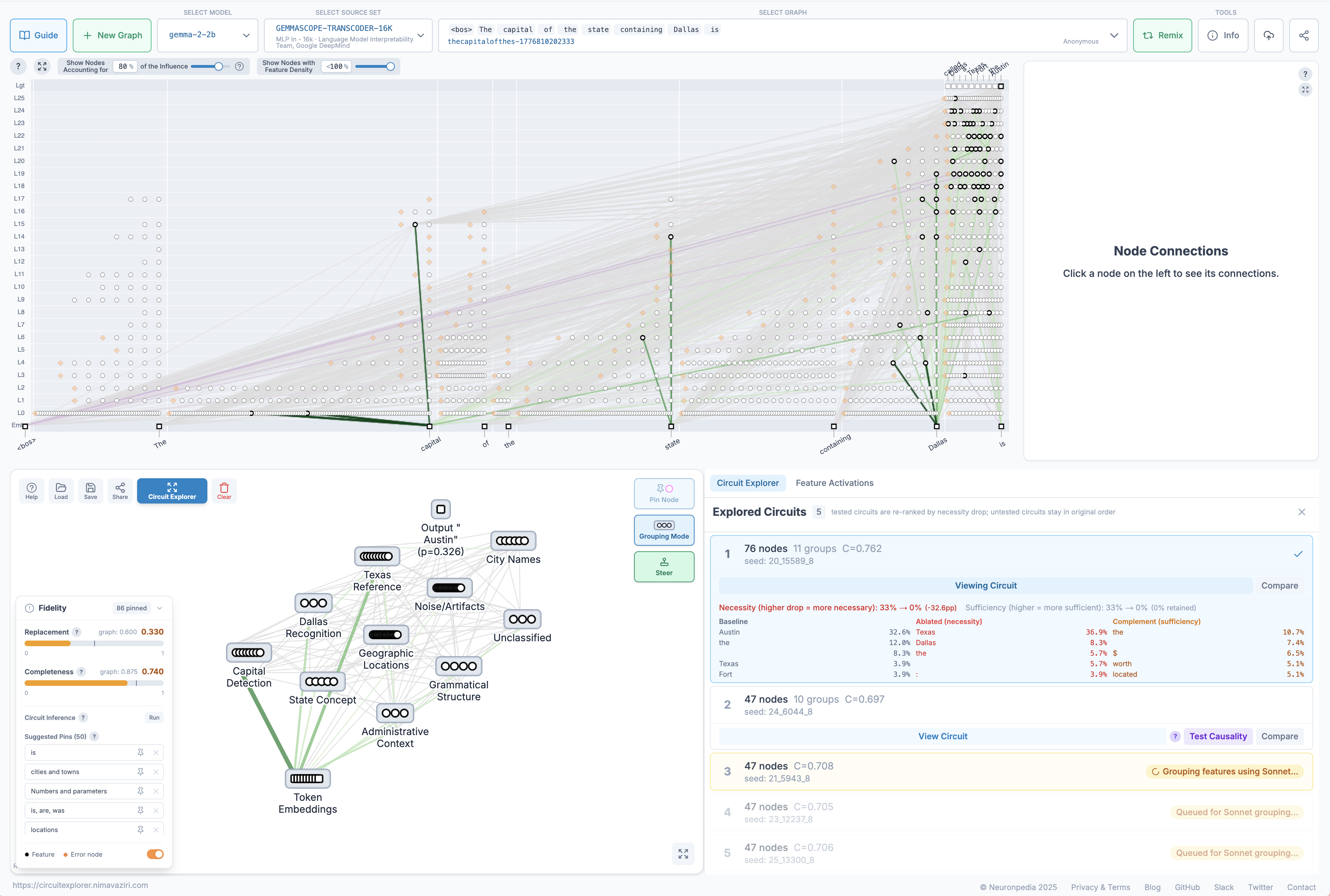 |
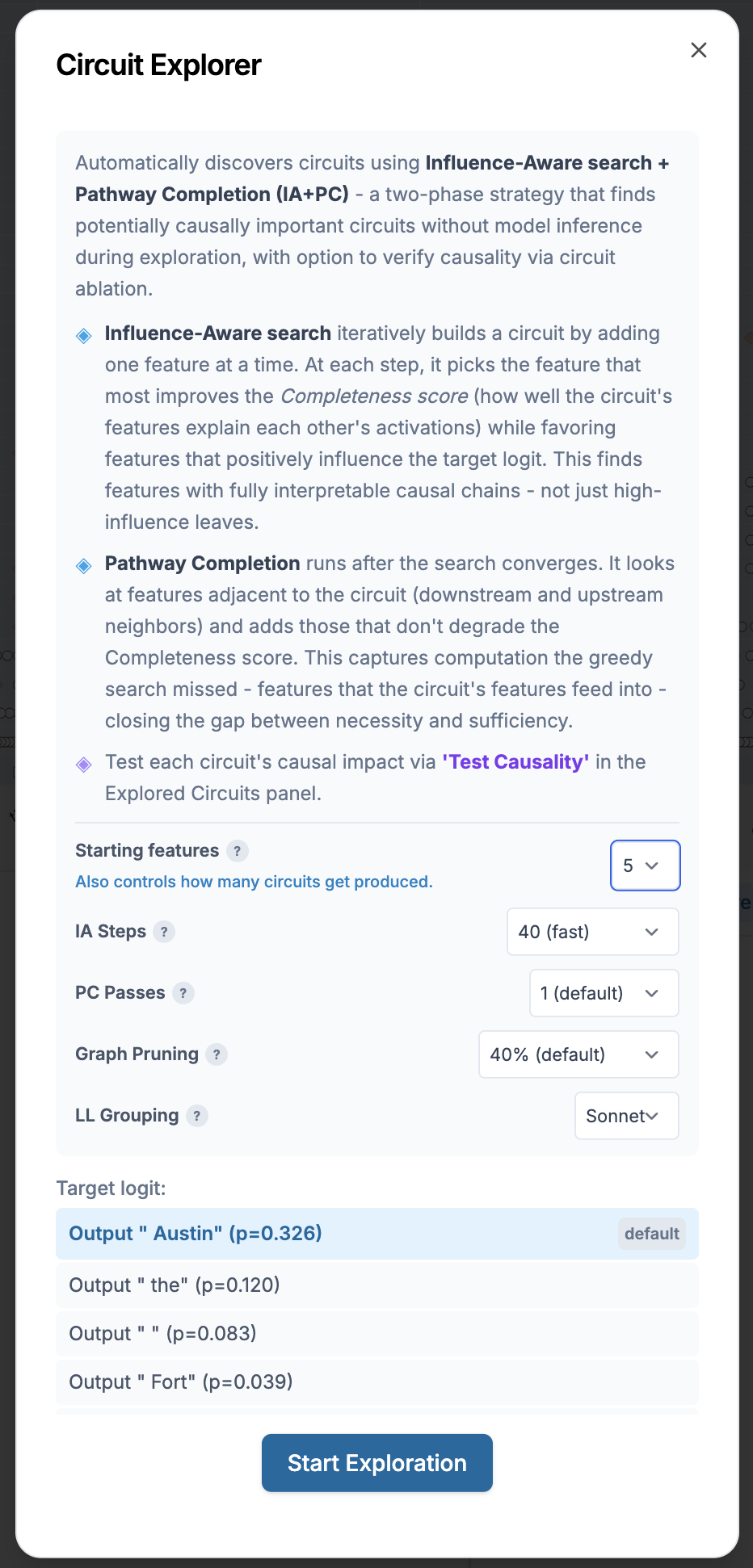
The main interaction is a Circuit Explorer modal launched from the graph toolbar. A researcher chooses the number of starting features, the IA search budget, the PC passes, and the graph-pruning threshold. The system then builds candidate circuits in the background and streams them into the sidebar as they finish. The researcher does not have to wait for a full batch before inspecting the first result.
The explored-circuits panel turns discovery into comparison. Each candidate circuit shows its feature count, completeness score, and grouping status. A researcher can apply a circuit to the graph, compare two candidates, or run causal validation directly from the panel.
| Building circuits | Circuits ready to inspect |
|---|---|
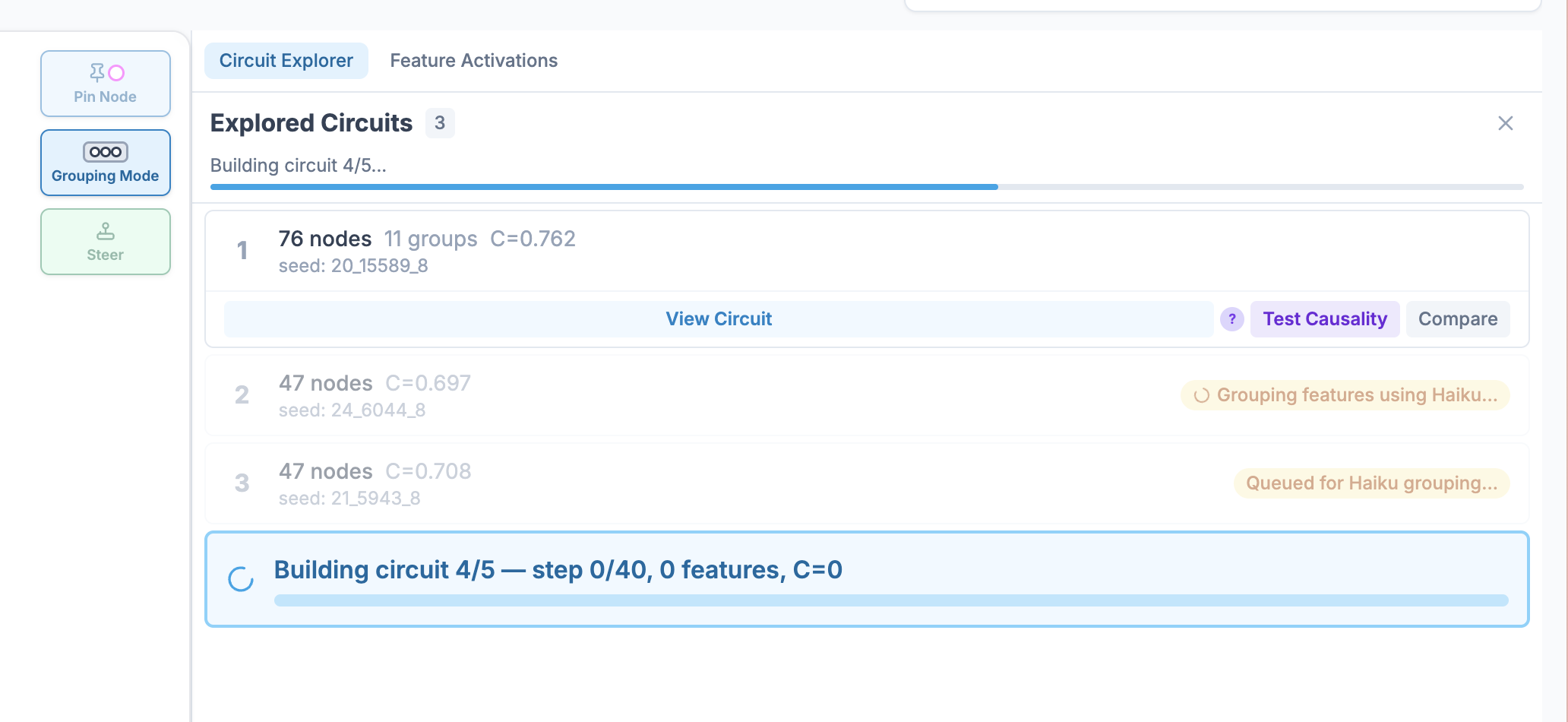 |
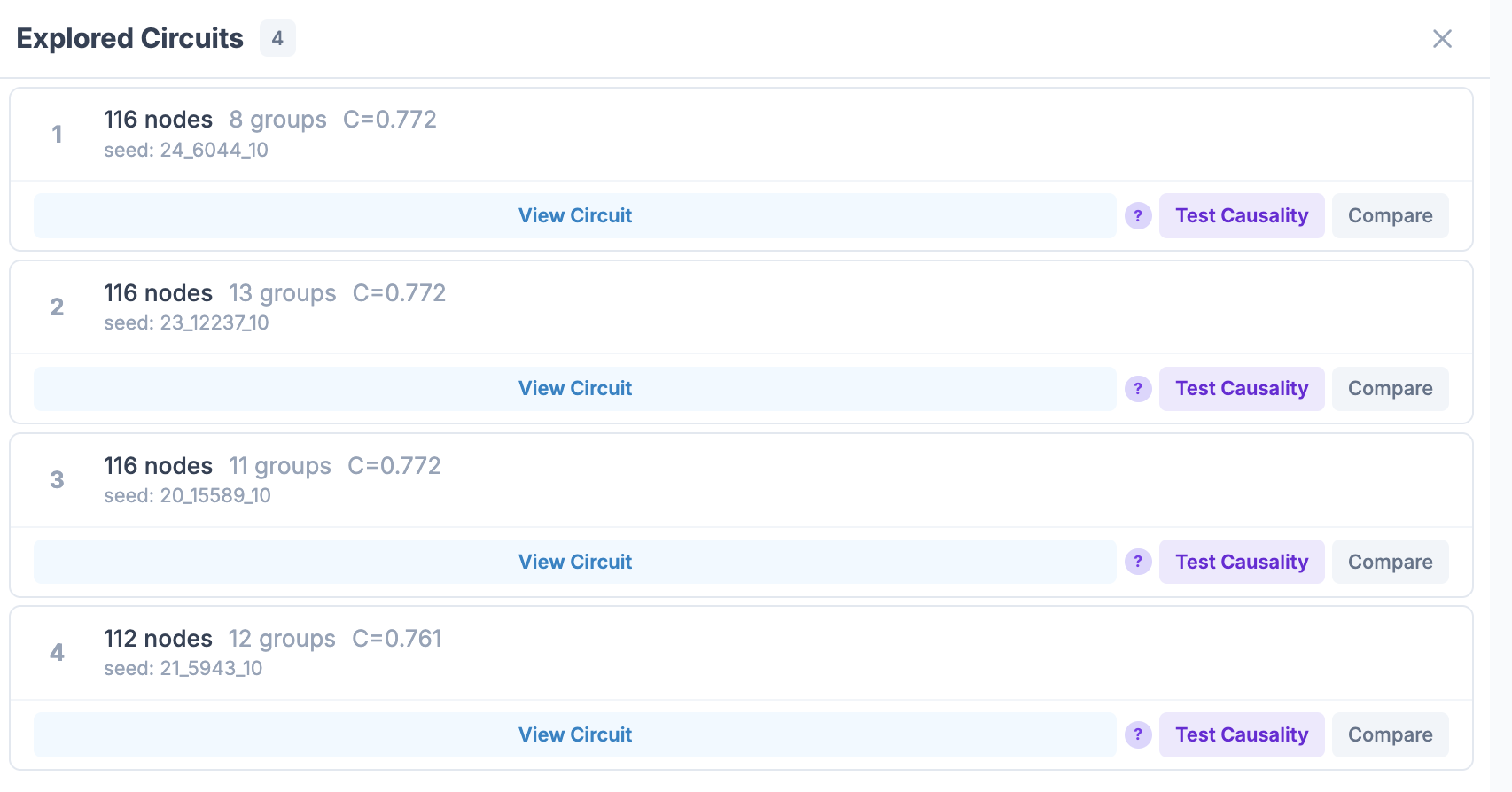 |
When a researcher clicks View Circuit, the full attribution graph is reduced to the selected circuit. Features are pinned and organized into semantic groups, so the researcher sees a structured mechanism rather than an undifferentiated set of nodes. They can expand groups, inspect feature labels and edges, edit pins, and keep refining the circuit.
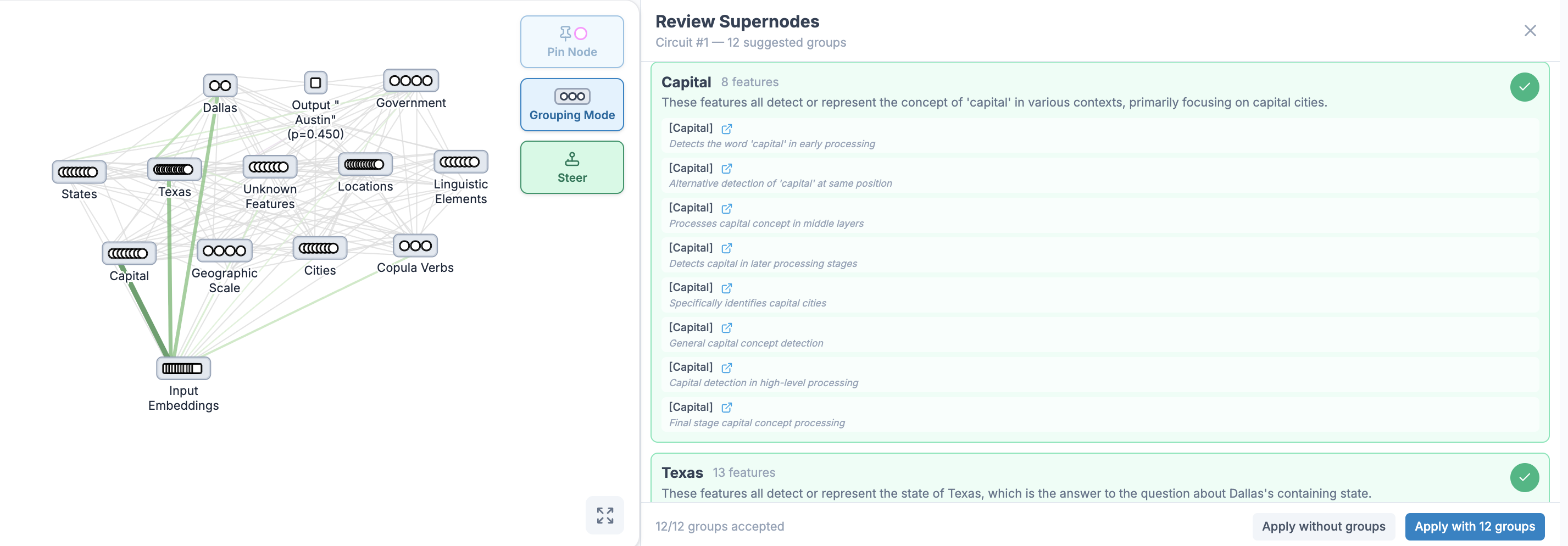
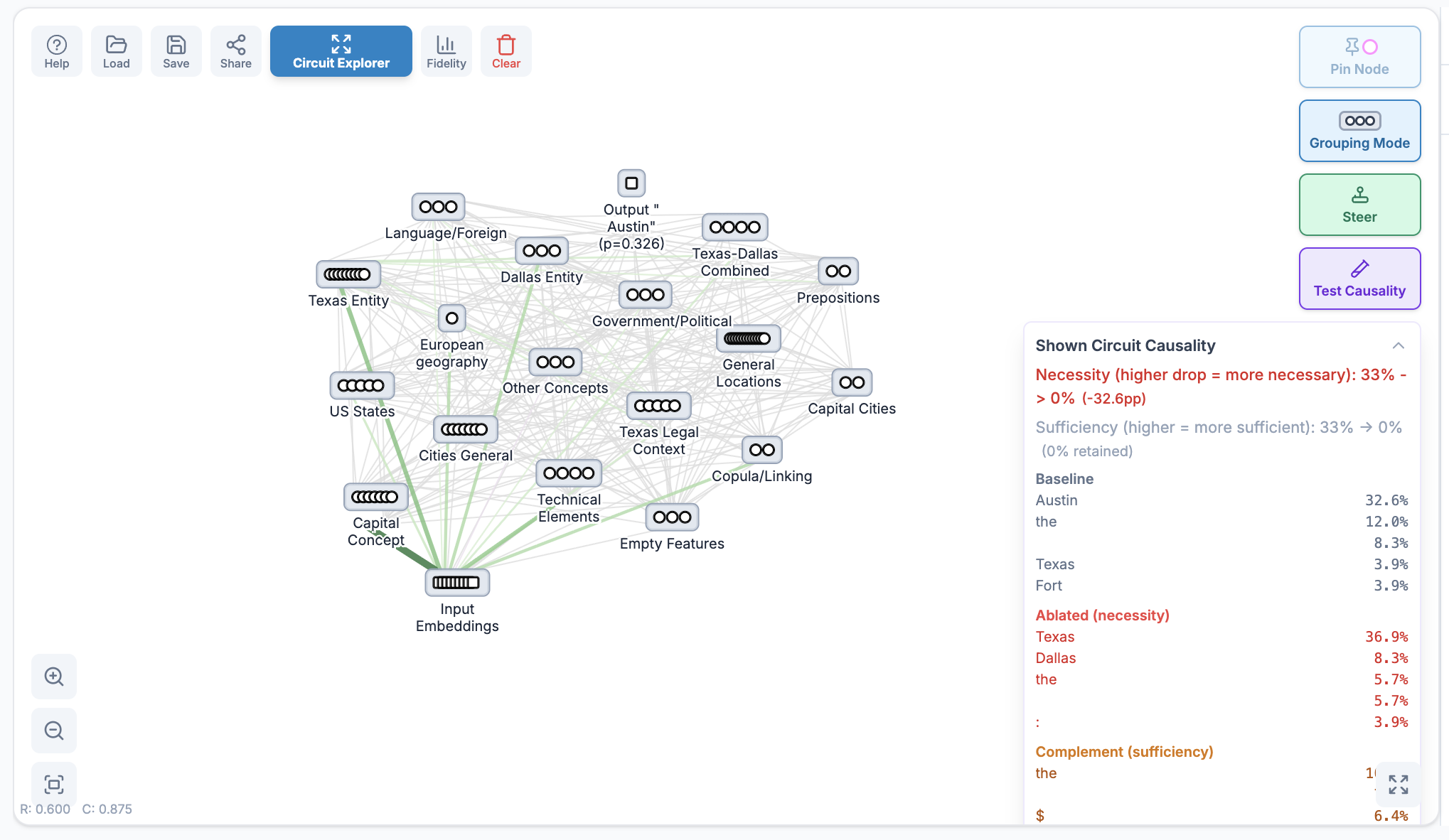
The validation loop is also built into the interface. Test Causality runs model inference for the baseline, circuit ablation, and complement ablation. The UI reports necessity as the target-probability drop when the circuit is removed, and sufficiency as the amount of target probability retained when only the circuit remains.

There's also a Test Causality button to the right of each circuit visualization. This allows the researcher to test the causality of just the displayed circuit, so the researcher can pin and unpin features as desired and test the causality of the resulting circuit. This creates a fast feedback loop directly in this interface compared to going to the steering panel, which is useful in its own way.
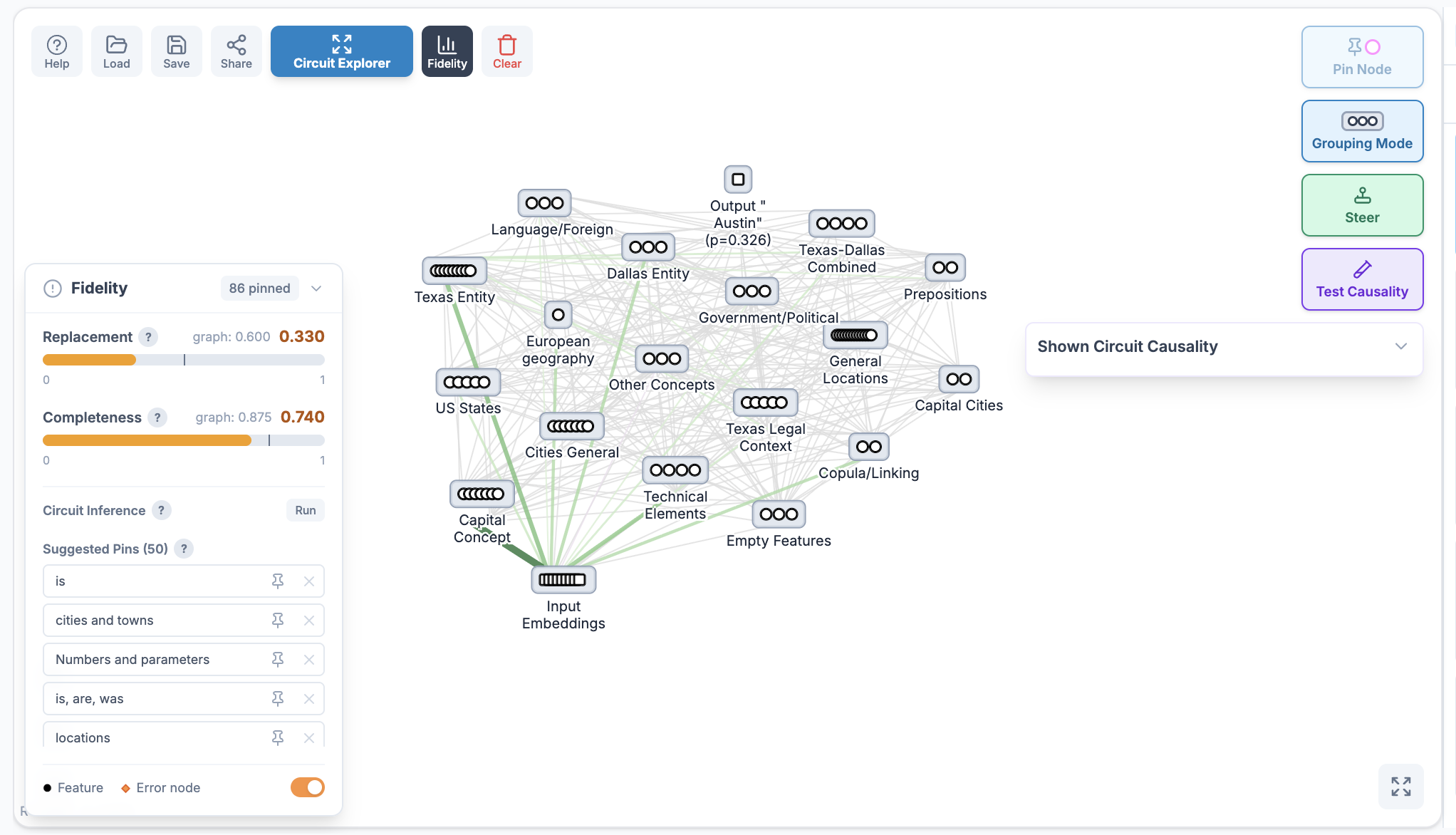
The other important UI component is the Fidelity Dashboard, which can toggled on/off. It gives live Replacement and Completeness scores as features are pinned or unpinned, suggests nearby pins that may close explanatory gaps, and can reveal error nodes so researchers can see where the attribution graph's explanation is incomplete.
That is the before-and-after difference. Before CircuitExplorer, the graph was mostly something a researcher manually navigated. After CircuitExplorer, the graph becomes a scored, searchable, editable circuit workspace: the algorithm proposes circuits, the UI makes them interpretable, and causal tests keep the interaction grounded in model behavior.
System Architecture
Since CircuitExplorer is an extension of Neuronpedia, it spans the full stack because the research loop spans the full stack.
The frontend is integrated into Neuronpedia's Next.js / React / TypeScript graph interface with D3 visualization. The graph and inference backend uses FastAPI / Python, PyTorch, TransformerLens, circuit-tracer, and transcoders for graph generation, circuit scoring, steering, and ablation-based validation. The platform layer uses Prisma / Postgres for persistence and metadata.
The important part is how the pieces line up with the research workflow, not the stack in and of itself:
- client-side Web Worker scoring gives live Replacement and Completeness feedback while a researcher edits pins
- server-side PyTorch scoring supports faster batch discovery and evaluation
- SSE streaming returns candidate circuits as they are built instead of waiting for a full job to finish
/steerand/steer-batchconnect circuit hypotheses to actual model interventions- the eval runner uses the same discovery and validation machinery as the UI, so interactive results and benchmark results are grounded in the same system
Do These Circuits Reflect Real Mechanisms?
A natural objection is that an automated circuit-discovery algorithm might just be finding correlated feature bundles.
Specifically this means the algorithm might be finding features that tend to show up together, without proving that those features are actually part of the causal mechanism producing the model’s answer.
Example:
Suppose the prompt is about Paris and the model predicts the token "France".
A correlated feature bundle might include features for:
- Eiffel Tower
- French language
- European capitals
- tourism
- Paris
Those features are correlated because they often activate in the same contexts. But not all of them are necessarily causally needed for predicting "France".
The actual causal circuit might rely mostly on:
Paris -> capital-of relation -> France
while "Eiffel Tower" and "tourism" are just nearby context features that light up because many Paris-related prompts mention them. If an automated method selects all of those together, it may look like it found a coherent circuit, but some selected features may be passengers rather than mechanism.
Detecting if the circuits reflect real mechanisms is why I ran the counterfactual prompt-pair analysis.
One such example is:
- "Bonjour means hello in" -> "French"
- "Hola means hello in" -> "Spanish"
The overlapping mechanism of interst here is likely a language-identification / translation-template circuit.
Across 40 prompt pairs, the results show a clear pattern:
- cross-lingual and multi-hop factual tasks show meaningful shared-feature overlap across prompt variants
- antonyms and parts of irregular morphology show near-zero overlap
In cross-lingual identification prompt pairs like “Bonjour -> French” and “Hola -> Spanish” share a substantial fraction of their circuit features, and the shared features are causally necessary for both outputs.
Transfer Beyond One Model
I also wanted to know whether the method was brittle to a single architecture.
On Qwen3-4B, IA+PC achieves comparable average necessity to Gemma-2-2B with no algorithm modifications:
- Gemma-2-2B: 0.360
- Qwen3-4B: 0.374
The category-level pattern also transfers: cross-lingual and factual recall remain strong, while attention-heavy categories remain weak.
The caveat is sufficiency. Qwen's sufficiency is much lower, which I suspect could be a transcoder quality / graph coverage issue, not a search issue. I don't want to overclaim broad model-independence from two models and uneven transcoder quality though. It's more appropriate to say:
the search method appears to transfer across architectures, while the achievable circuit quality remains bounded by the fidelity of the underlying replacement model
The Main Failure Mode
The clearest weakness is analogy-style prompts such as:
Mexico:Spanish :: US:EnglishMexico:peso :: US:dollar
These are the cases where researcher-built circuits still beat IA+PC.
The failure mode appears to be suppressive-feature contamination: the search can pick up features that help the target mainly by suppressing competitors, rather than by participating in the target mechanism itself. More broadly, high-sufficiency circuits can also include infrastructure features that keep the residual stream functional under heavy ablation without actually being part of the mechanism of interest.
This points to the most obvious next method step:
explicitly distinguish core mechanism features from suppressive and infrastructure features
What This Shows
I think CircuitExplorer supports three claims.
First, attribution-graph circuit discovery can be automated for a meaningful class of MLP-represented mechanisms. Manual circuit tracing does not have to be the only option.
Second, fast graph-based search can preserve causal quality. Matching expert necessity while improving sufficiency is the strongest evidence for that.
Third, good interpretability tooling should surface its own epistemic limits. It's clear that:
- analogy prompts expose suppressive-feature contamination
- antonyms and some syntactic tasks are likely not best understood via MLP-based reconstruction and might be better undertsood if attention gaps were closed
- cross-model transfer shows promise for where the method could be robust and where transcoder quality might become the bottleneck
What I Would Do Next
The UI is already central to making the method usable, but the highest-leverage next step is methodological: make the discovered circuits cleaner.
I would add a feature-role scoring layer that tries to classify discovered features as:
- core
- suppressive
- infrastructure
Then I would test whether those labels improve analogy prompts without hurting the strongest categories.
Of course having higher quality CLTs for the model at hand is highly relevant as well, so exploring that would be a function of its required activation energy.
Closing
CircuitExplorer started as a way to make circuit analysis less painful. It turned into a research-engineering system for automating, evaluating, and stress-testing circuit discovery from attribution graphs for some prompt categories.
The result I care about most is that it is faster than the baseline workflow and that the system can recover researcher-equivalent causal circuits, while presenting them in a form researchers can actually work with, and make its own limits visible.
As interpretability research engineering goes, the bar to hit is: build infrastructure that lets researchers ask sharper questions, run interventions faster, scale evaluation beyond hand-built examples, and expose failure modes clearly enough to improve the science.